正規表現とオートマトン
正規表現

1番と2番は簡略化されてますがどちらも他と同様language、つまり集合であることに注意します。(正確には、例えば正規表現に対して言語
とするようです)
また、は「空文字列」という一つの文字列を含むlanguageであるのに対して、
は何の文字列も含まないlanguageということです。前回出てきたunionとconcatenationを使えば、
となるようです。 (empty set)は「何の文字列も受理しない」ということなので、分岐したところで何も効果はなし、対して
(empty string)は「空文字列のみを受理する」ので、既存の正規表現に後続させても何も効果がない、、まあ、初めはこれくらいの砕けた言葉で理解しても良いでしょう。例えばこれを逆にすると、前者はRのみならずεも受け入れてしまうことになってしまいますし、後者だとRも含めて何も受理しなくなってしまうって感じですかね1
また、
で、正規表現における「0文字以上」のと「1文字以上」の+を数学的に表現できるようです。空文字列を使えば、[tex: R^{+}\cup\epsilon =R^{}]という関係になりますね。
基本的にプログラミング言語における正規表現を知っていれば大丈夫っぽいですが、empty setと*の細かい扱いにはちょっと注意ですね。

正規表現と有限オートマトンの表現力は同等

「regularである」は「それを認識する有限オートマトンが存在する」です。こういうのは何回も書かないと慣れないですね。。
まず正規表現→regularの方ですが、こちらは先ほど述べた正規表現の6つの定義それぞれから、それらを認識するNFAを構築すれば良いことになります。正規表現に対して、言語
を認識するNFA
を形式的に構成します。
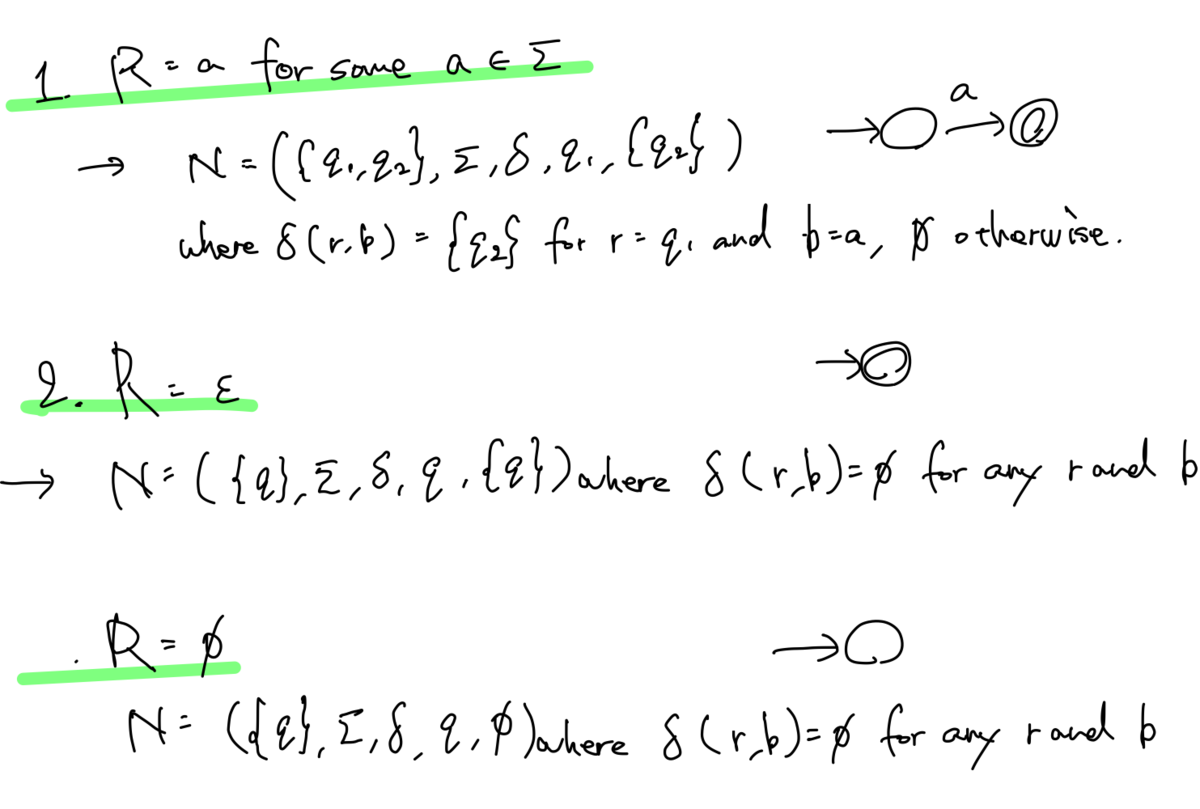
といっても、4,5,6は以前構築した3つのNFAをそのまま適用するだけなので、ここでは割愛です。
GNFA; Generalized nondeterministic finite automata
regular→正規表現はこれよりちょっと大変でした。 まず、NFAと正規表現の間に挟む、GNFAというオートマトンが導入されます。

DFA, NFAと比較すると、やっぱりが拡張されています。また、
が集合ではなくone stateになっていることもポイントです。
の引数・戻り値の型から、[tex:(q{accept},q{start})]の組合せを除く全てのstate有向ペア(自己投射を含む)に1つずつ正規表現ラベルが割り当てられていることが分かりますね。2


正確にはこの3条件はGNFAの「特殊形」ということですが、まあすんなり理解できる感じの特徴ではあります。
証明は、一旦任意のDFAをGNFAに変換した上で、このGNFA特殊形の性質を使って正規表現へ変換していくという形をとるようです。
DFA to GNFA in the special form
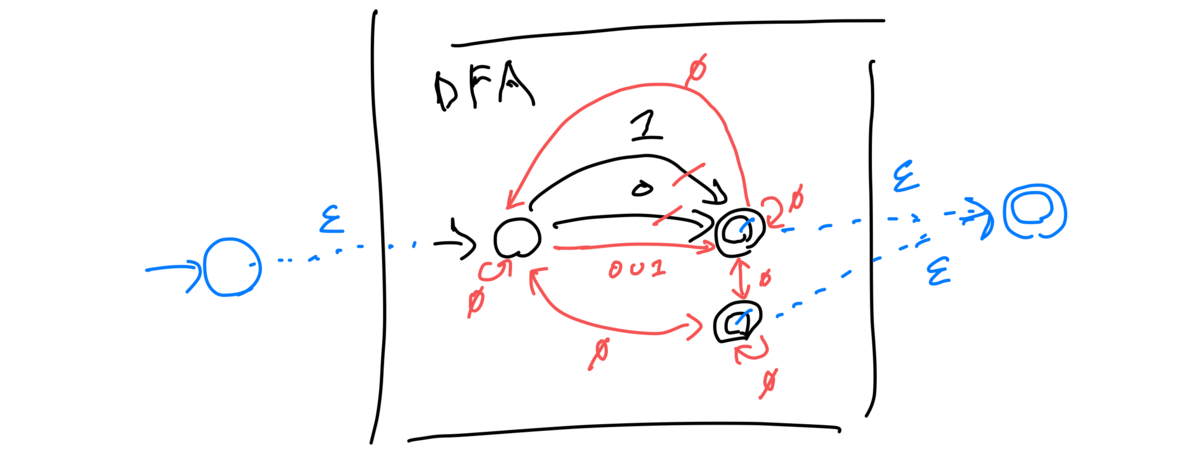
始状態、終状態を新たに作って、矢が複数あったら1本にまとめる、1本もないところはラベルで付け足す。この4操作でGNFAに変換できます。簡単ですね。
CONVERT(G)
続いて、正規表現への変換関数CONVERTを用意します。
CONVERT():
Let
be the number of states of
.
If
, return the expression
with which the single arrow connecting a start and accept state is labeled.
If
, return CONVERT(
) where we construct GNFA
by selecting any state
except for
and letting
3の工程で状態数が1つ減るので、それをk=2になるまで再帰的に呼び出しています。の戻り値が正規表現なので、()で囲んで*で0文字以上とか指定しているところに注意です。
の定義がミソですね(下図参照)

この過程でGNFAの同値性が保たれる(同じ言語を認識する)ことが理解できれば、あとはinductiveにこれがk=2まで降りてくることが証明できます。
Nonregularity
GEB読書メモ 形式システムと諸々の創発的特性について
形式システムと知能の関係について
P308
「コンピュータはしろと言われたことしかできない」という古い金言があるが、これは次の2つの点を見逃している。すなわち、我々はコンピュータに「しろ」と言ったことの結果をあらかじめ分かってはいない(場合がある:例えば円周率を計算するプログラムは、円周率の値を知っていれば実行する意味がない)。また、プログラムが複雑になればなるほど、我々はコンピュータに何を「しろ」といったのか明確には分からなくなるということだ。
P561,562
外界の事象の知的な内部表現を達成するためのプログラムの開発には、直接的な解釈ができない(現実の要素には直接対応付けられない)構造や過程を使わざるをえないだろう。心象及び類推の思考過程は、演繹的推論のように「最高レベルをすくいとる」ことはできない:創造性はある種の解釈不可能な低レベルの事象に決定的に依存している。
コメント
今日の人工知能の発展を牽引しているニューラルネットについて考えると、上記の事柄がより実感を持って理解できる。例えば、NNは円周率の計算と同様に、その出力の正確な値自体は事前に知らないタイプのプログラムである(逆:計算機の信頼性と速度を基盤とした「機械的な」応答をするシステム)。また「機械的な」システムと違ってプログラム自体がコードレベルで命令の内容と意図が理解できるものではなく、ニューロンや層といった高レベル記述に頼らざるを得ない。
さらに決定的なのは、NNの解釈性(説明可能性)についてである。恐らくモデルの登場時から長らく議論されてきたであろうこの問題は、我々の「直観的な」理解を超えた解釈不可能な状態ネットワークこそが、知能のもつ掴みどころのない高次的機能を生み出しているという考えを強力に支持するものだと思われる。
著者は「すべての人を打ち負かすチェス・プログラムは(中略)できないだろう」(P667)と予想している。チェスですべての人を打ち負かすプログラムは、チェス以外の全く関係ない事柄にも興味を示すような、全体的な概観能力をもった一般的知能(いわゆる汎用AI)になるだろうと考えていたようだ。この考えは第3次AIブームの初期段階で否定されてしまうが、この強力な手法をもってしても汎用AIへの道はいまだ見えてこないという事実から、知能の要件(学習、創造性、感情的反応、美的感覚、自我意識等)について今一度検討する必要性が示されているのではないか。
その他、話題にしたいこと
- 心の本質は自己認識や自己改変が可能なことにある。この事実はすぐさま「自己認識を行っている自己を認識する自己を...という無限連鎖」を想起させるが、心は出来の悪いプログラムのように無意味な無限退行に陥ったりはしない。このことは、心が自己言及できるシステムを含むさらに強力なシステムに支配されていることを表す(?)
ちょうどプログラムがプロセッサというハードウェアを前提としているように、脳というニューロンが固定配線されたハードウェアによって「底入れ」されている。
- 全く選択の余地がなく物理法則に従ったのみなのか、自由意志によるものなのか。なぜそのような感覚の違いが生まれるのか
自由意志は自己認識と自己無知の間に生じる。生理反応や無条件反射のような全く己の感知しない行動に関して自らの「選択」を感じることはないが、反対に自己と外界の全ての物理を把握している意識が仮にあるとすると、これも「選択」している感じは生まないだろう。
「意味」は単独では存在できない。図と地。禅。DNA及び複製プロセスの実現。
資本主義社会は人間に「取り換えが効く」という感じをもたせてしまうことによる弊害が非常に大きいことがますます明らかになってきている。そのような悩みが競争心や独創性を働かせることは言うまでもないが、行き過ぎたそれは不可避的に実存的不安をもたらす。
ところで、実際人間の脳はどの程度取り換えが可能なのか?ミミズなどの虫では神経細胞の数は1000程度であり、その神経細胞1つ1つがどの個体でも対応するらしい。人間の脳も解剖学的なレベルではほぼ完全な同型対応がとれるものの、それより下のレベルでは全くそのようなことは不可能で、実際我々がものを考える仕方は人によって相当に異なっている。
学習メモ:非決定性有限オートマトン
東京大学工学部モラトリアム養成学科の学生です。フリーでプログラマをやったりしていましたが、CSの知識は一切ありませんので、色々教えてもらえると幸いです。英語も全くネイティブではありませんが、世界標準なので使っていきます。1
読んでいく本
※ 私が重要だと思った点を適当にまとめていく形になります。リファレンス的利用を想定しています。
Regular Languages
we use an idealized computer called a computational model... We begin with the simplest model ,called the finite state machine or finite automaton.
さすがにオートマトンくらい何度か聞いたことはありますが、これが全ての計算機の最小モデルなんですねー。状態遷移図の一般化みたいな感じですかね。

Formal Definition of A Finite Automaton
イメージで語っても仕方ないので、辛いですが定義を見ていきます。

と
がそれぞれ「状態」と「入力信号」の集合で、遷移の仕方を規定するのが関数
、そして
の中で始状態
とaccept状態の集合
がある感じですね。まあ必要十分という感じがします。
オートマトンには、acceptという動作があるようです。早速上記の定義が使われています。

例えば、が文字列
hogeだったらは
h、は
oという感じに分解されて、この文字列がacceptされるかどうかは、「状態から出発して、関数
に現在の状態と次の入力信号を渡しながら状態を更新していき、最終的にaccept状態のいずれかにあるか否か」ということですね。
オートマトンは正規表現
automaton, acceptなどが分かったところで、次の定義を見ていきます。
If A is the set of all strings that machine M accepts, we say that A is the language of machine M and write
. We say that M recognizes A.
ちょっと最初この文章がしっくり頭に入ってこなかったんですが、どうも状態遷移図のような先入観はあんまり良くないですね。
オートマトンは状態遷移図のようにただ遷移の様子を分かりやすく表すことが目的というよりは、「入力信号を分解してacceptか否かに振り分ける」ということで、どちらかというと正規表現って感じです。
(→正規表現と有限オートマトンは同値のようです。直感的には当然ですね。)
NFA; Nondeterministic Finite Automata
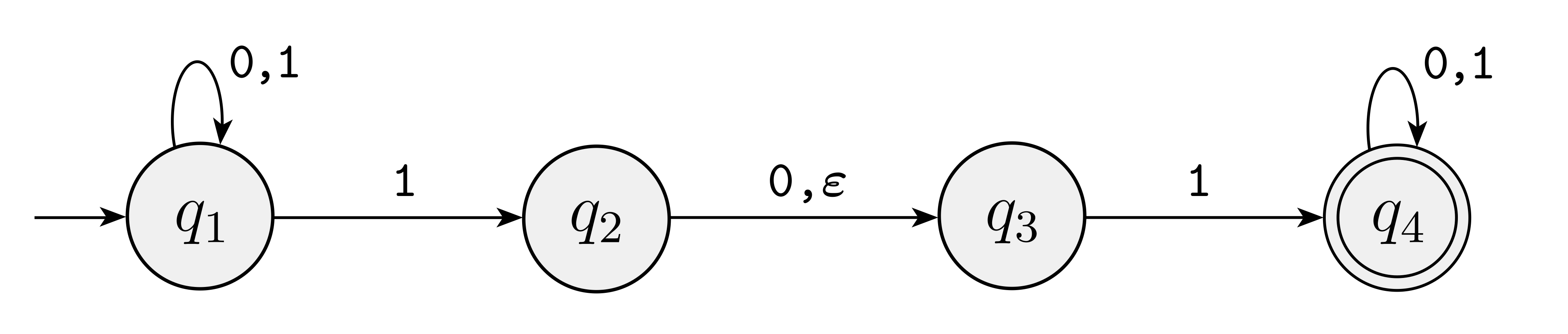
非決定性有限オートマトン(NFA)ですね。ちなみに決定性有限オートマトンはDFAです。
1. 1つの状態からの各alphabetに対応する矢印数が0~複数 2. [tex:\epsilon]という自動で遷移する特殊なラベルが追加
という2点で拡張がなされています。あくまで拡張なので決定性オートマトンも非決定性の一部という感じのようですねー。2
形式的な定義は以下になります。

DFAと比べて変化しているのは3番のみです。は
を、
は
の全てのsubsetの集合をそれぞれ示しています。
先ほど述べた、「1. 1つの状態からの各alphabetに対応する矢印数が0~複数」は値域の、「2.
という自動で遷移する特殊なラベルが追加」は定義域の
に反映されているということですね。
実は全てのNFAは同等の(同じ言語を認識する)DFAに変換できるということですが、以上述べた非決定性の拡張によって、多くのオートマトンの表現が簡潔になるようです。
役割分担
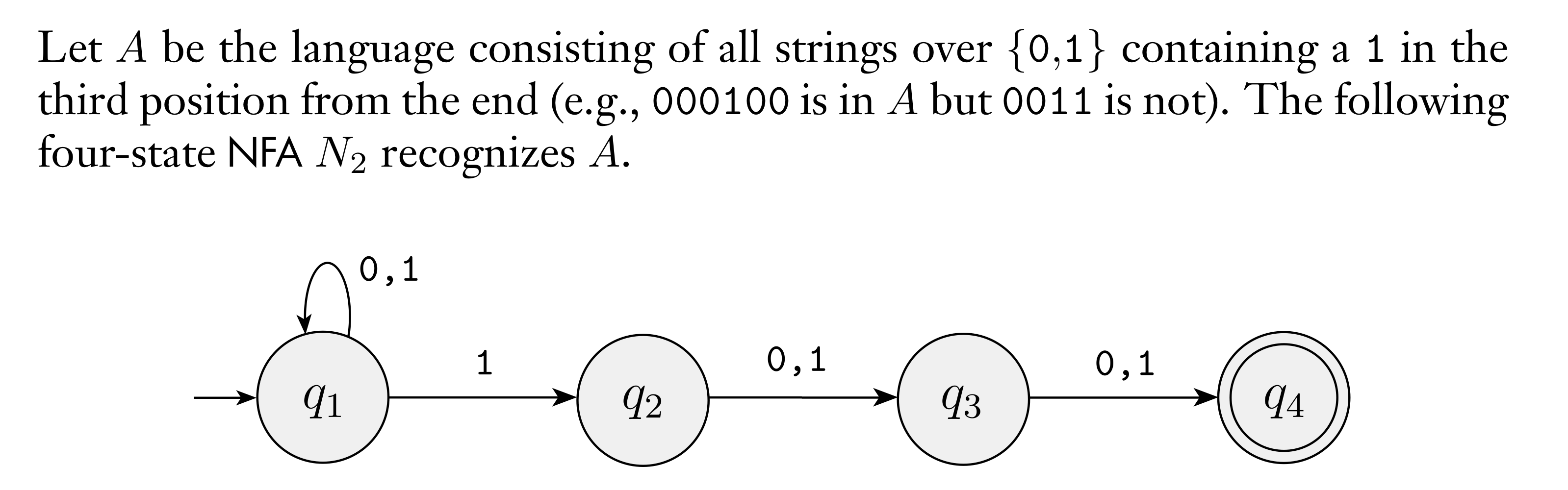
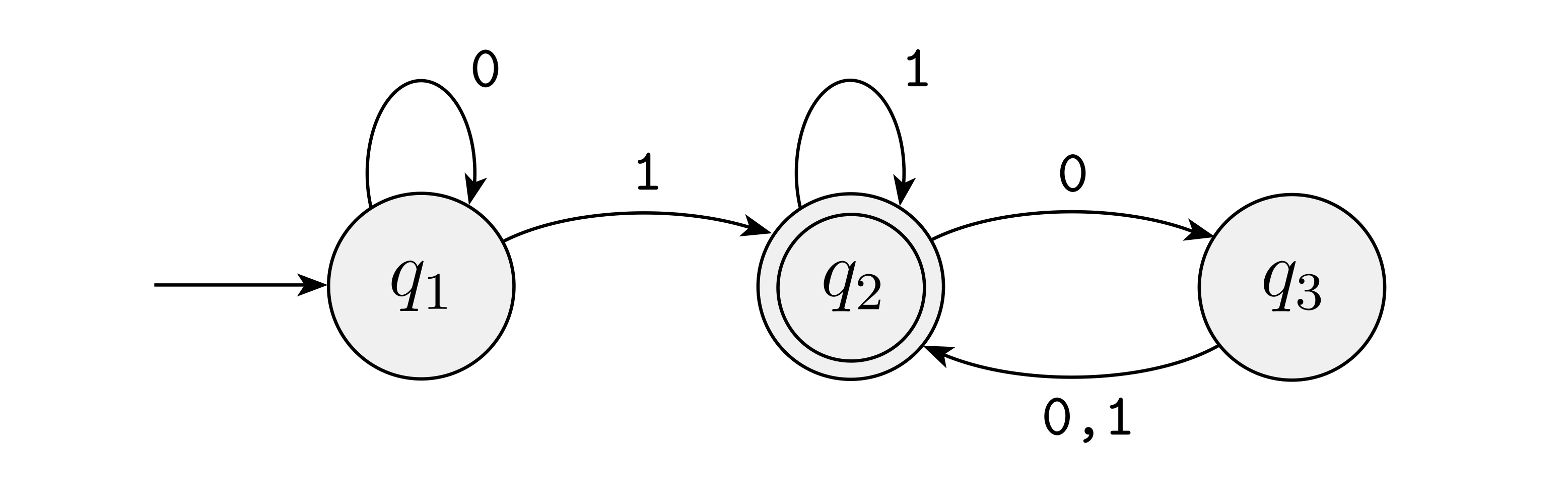
"language"は集合であることに注意していきます。はバイナリの中で「末尾から3番目に1がくる」文字列の集合のようです。これを認識するには、1を検知して、その次に2つのみ0または1が続いて終了すればacceptしたいということです。
厄介なのは、最初に検知した1の次にくる文字になります。例えば、"110"ときてその後にもう一度"0"が来た場合、最初の1は末尾から4番目になって候補から外れますが、その隣の1は候補に入っているわけです。
この手順をシンプルに表現するには、検知した複数の1を独立に評価できると良さそうです。そこで、上図では入力が0でも1でもに居続けながら、1だった場合はその都度分岐して2文字後に終わるかどうかチェックする手筈になっているわけですね。
ちなみに、上記のNFAをDFAで書き換えると以下のようになるようです。 うーん、コードでもいつの間にこんな書き方になってることある!気をつけたいです。
Every NFA has an equivalent DFA.
次はより一般的に、NFAからDFAへの変換を行なっていきます。
Let
be the NFA recognizing some language
. We construct a DFA
recognizing
:::note 準備として、εを考慮するためにちょっとした関数を用意します。 :::
For let
can be reached from
by traveling along 0 or more
arrows
.
それでは実際にDFAを構築していきます。なお、入力集合は同じですので、残りの4つを扱います。
.
.
.
.
ここら辺で皆さんが置いていかれないように(訳:私が適当にスルーしてしまわないように)丁寧に進んでいきます。
まずは状態集合でした。NFAでは複数の状態を同時に取ることができます。例えば
と
の両方にいるという「状況」をDFAで表現するためには、
という部分集合を1つの「状態」として扱う必要があります。従って、状態集合としては、それらの部分集合の集合である
となります。
次に、は「現在の状態と次の入力信号を受けて次の状態を返す」関数でした。
NFAでは、「1~複数の状態から、それぞれが1つのalphabetを受けて0~複数の状態へ遷移、さらに遷移後に
矢があればさらにその先へ分岐遷移」という形をとります。これが構築中のDFAの場合は、引数
がそれ自体部分集合になっていて0~複数の状態を表せます。戻り値は、その部分集合
の各要素状態
を個別にNFAの
にかけて、さらに
のために
をかませてから論理和をとったものになっています(適当にイメージを描いてみた↓)。

次のは素直ですね。状態集合
に合わせ
を集合にし、
があったら事前に遷移させます。
最後のは、部分集合の1つでも元のNFAでacceptであれば良いということで、直接的な定義になっていますね。
Closure Under The Regular Operations
NFAをうまく扱えば、正規言語3の性質も容易に示すことができるようです。

※ もう一度書きますが、"language"は「集合」です(あるオートマトンが受理する全ての文字列の集合)。
例えば、正規言語がこれらの操作に閉じている(これらの操作後もregularである4)ことが示せます。
Union
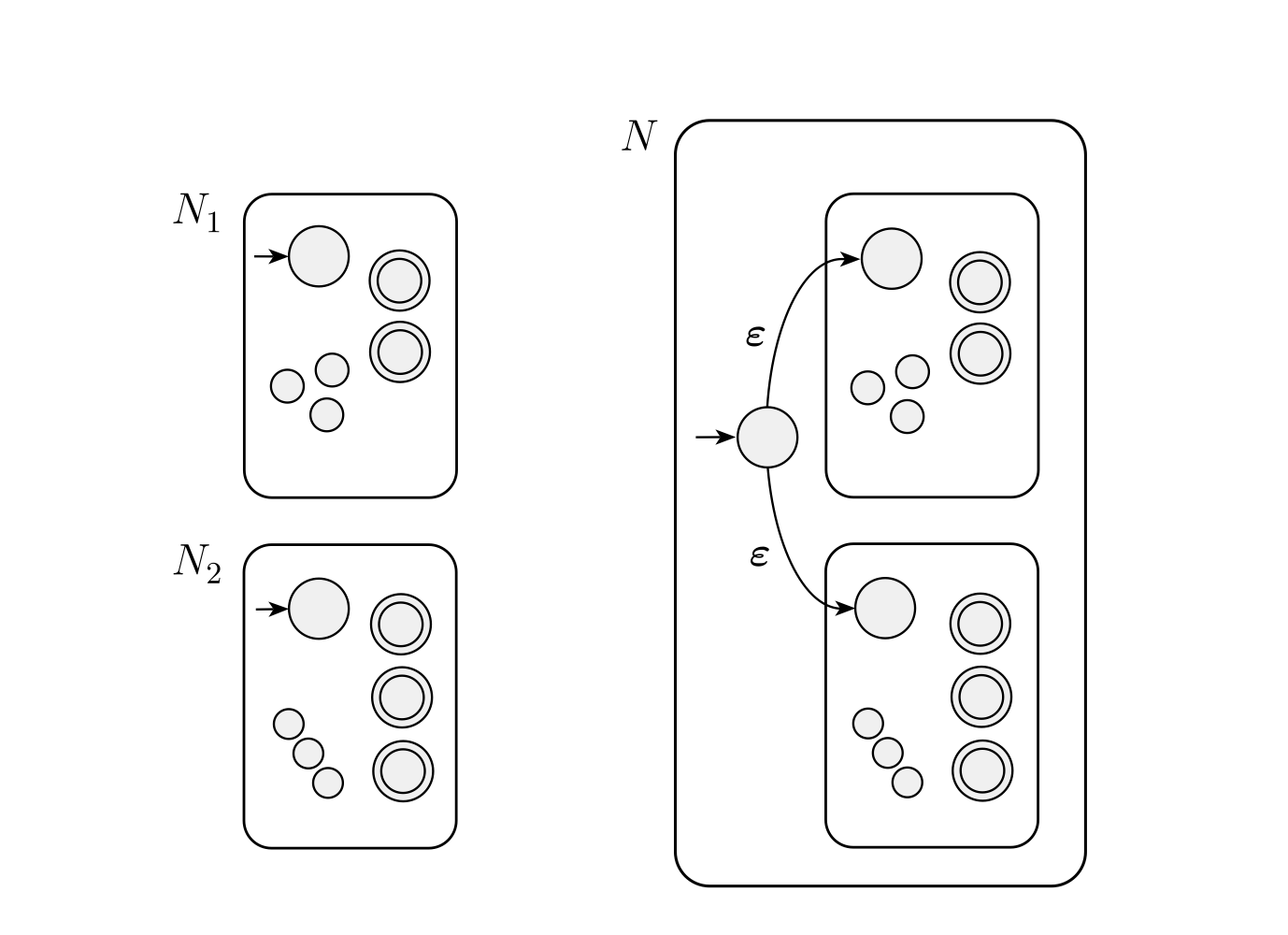
上記の構成でが
を、
が
を認識するとき、
は
を認識(その集合の要素を全てaccept)します。
の形式的な構成も書いてみます。
is the start state of
4.
Concatenation
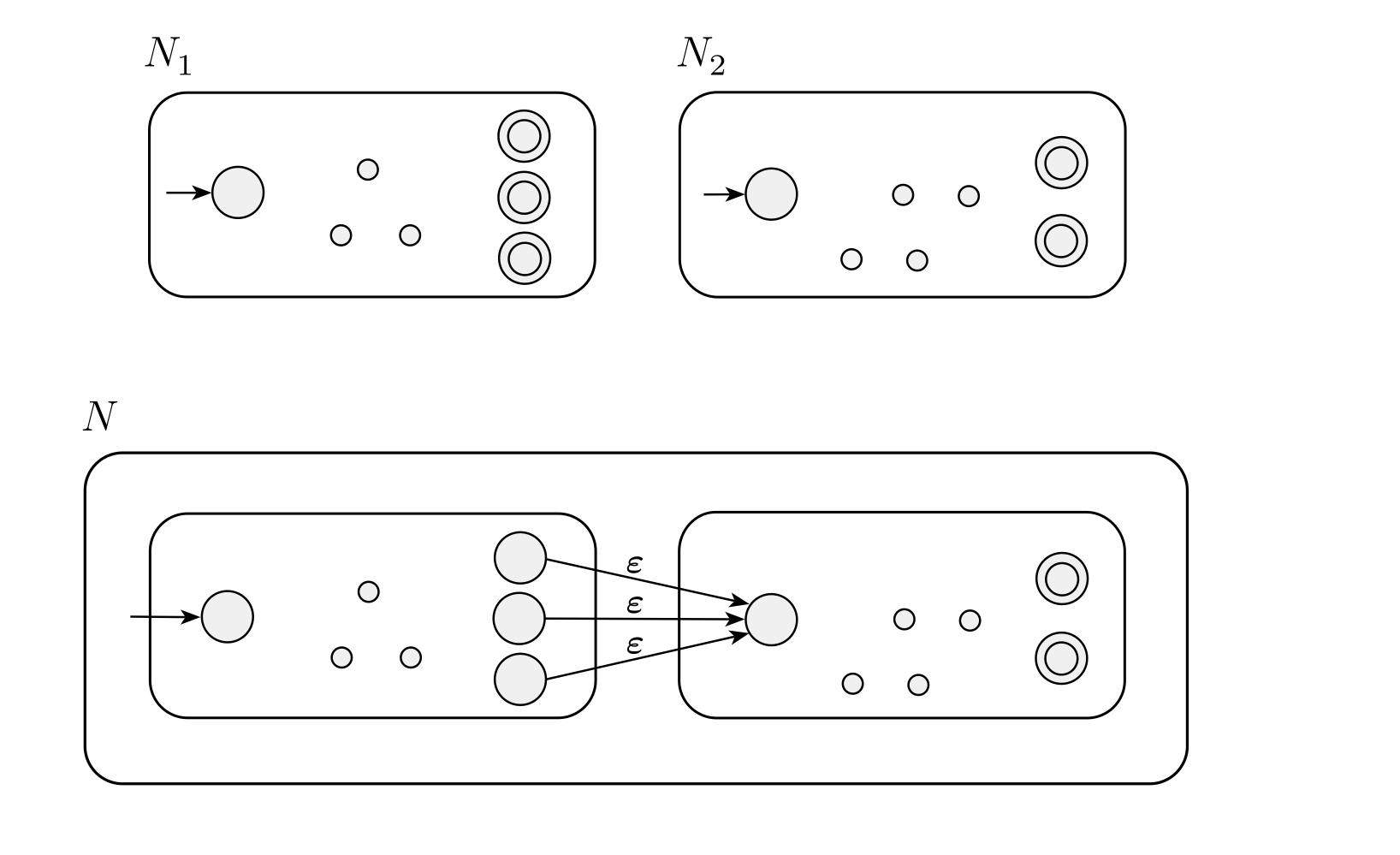
のaccept状態をただのstateに戻し、そこから続けて
をacceptするかチェックしています。
で一度accept状態になったとしても、そこから
の別のaccept状態に移ったりすることも考えられるので、
による分岐が必要になりますね。
4.
Star
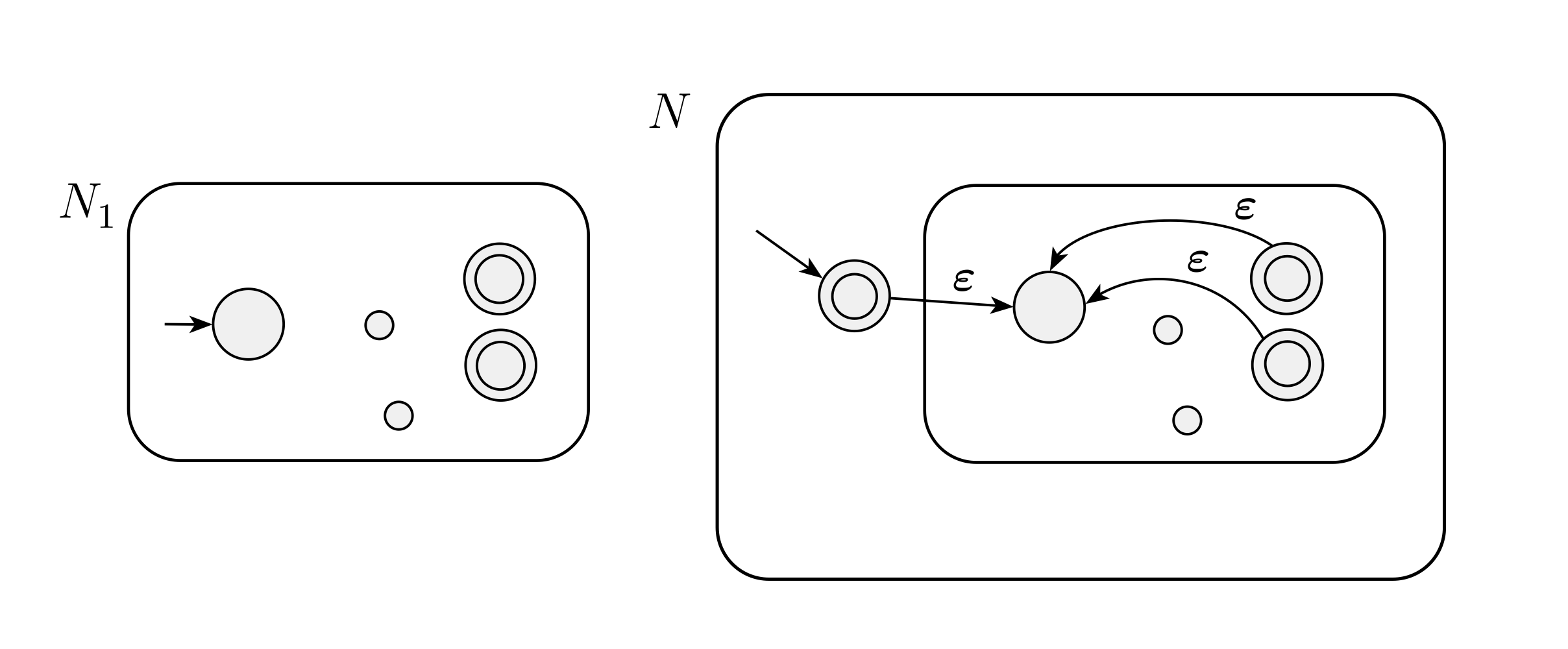
ならば
となるので、始状態をacceptにして、入力が始まればそこは死んで
部分のみ動くようになってますね。そこから任意の
のacceptを任意の回数連続させたものを認識できるようになっているようです。
4.