正規表現とオートマトン
正規表現

1番と2番は簡略化されてますがどちらも他と同様language、つまり集合であることに注意します。(正確には、例えば正規表現に対して言語
とするようです)
また、は「空文字列」という一つの文字列を含むlanguageであるのに対して、
は何の文字列も含まないlanguageということです。前回出てきたunionとconcatenationを使えば、
となるようです。 (empty set)は「何の文字列も受理しない」ということなので、分岐したところで何も効果はなし、対して
(empty string)は「空文字列のみを受理する」ので、既存の正規表現に後続させても何も効果がない、、まあ、初めはこれくらいの砕けた言葉で理解しても良いでしょう。例えばこれを逆にすると、前者はRのみならずεも受け入れてしまうことになってしまいますし、後者だとRも含めて何も受理しなくなってしまうって感じですかね1
また、
で、正規表現における「0文字以上」のと「1文字以上」の+を数学的に表現できるようです。空文字列を使えば、[tex: R^{+}\cup\epsilon =R^{}]という関係になりますね。
基本的にプログラミング言語における正規表現を知っていれば大丈夫っぽいですが、empty setと*の細かい扱いにはちょっと注意ですね。

正規表現と有限オートマトンの表現力は同等

「regularである」は「それを認識する有限オートマトンが存在する」です。こういうのは何回も書かないと慣れないですね。。
まず正規表現→regularの方ですが、こちらは先ほど述べた正規表現の6つの定義それぞれから、それらを認識するNFAを構築すれば良いことになります。正規表現に対して、言語
を認識するNFA
を形式的に構成します。
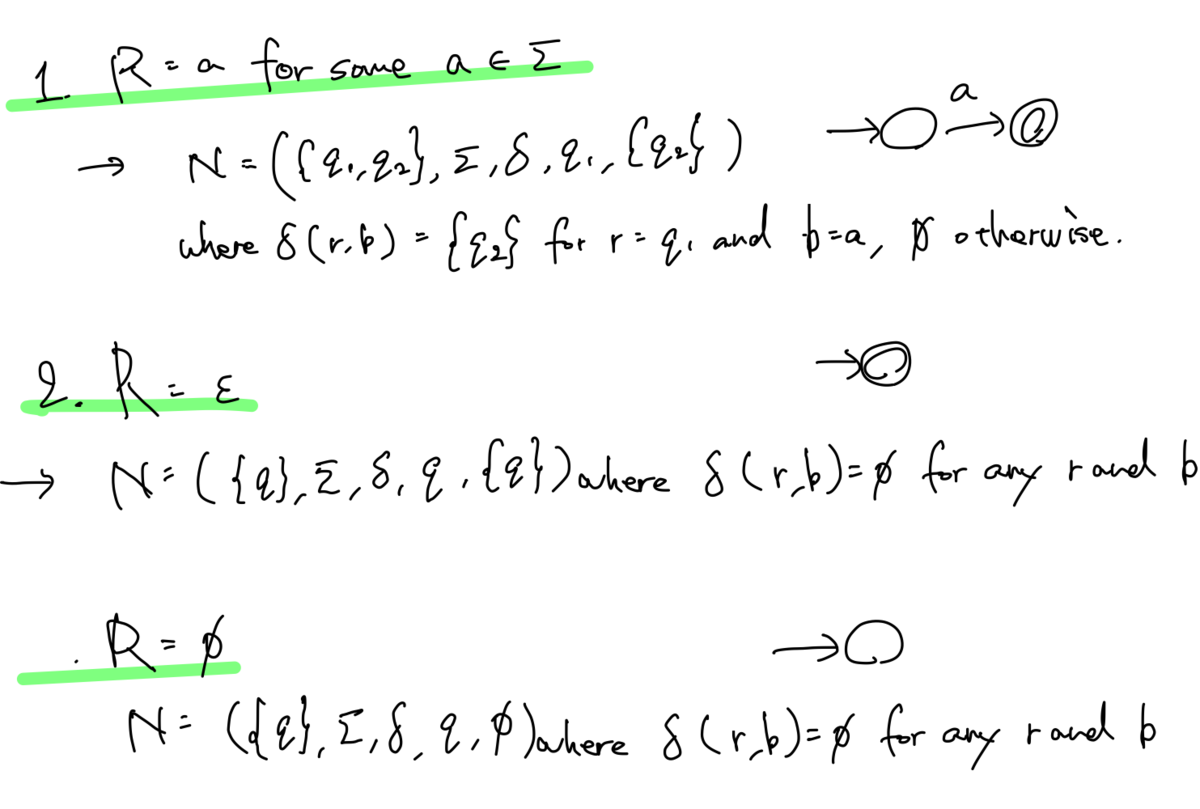
といっても、4,5,6は以前構築した3つのNFAをそのまま適用するだけなので、ここでは割愛です。
GNFA; Generalized nondeterministic finite automata
regular→正規表現はこれよりちょっと大変でした。 まず、NFAと正規表現の間に挟む、GNFAというオートマトンが導入されます。

DFA, NFAと比較すると、やっぱりが拡張されています。また、
が集合ではなくone stateになっていることもポイントです。
の引数・戻り値の型から、[tex:(q{accept},q{start})]の組合せを除く全てのstate有向ペア(自己投射を含む)に1つずつ正規表現ラベルが割り当てられていることが分かりますね。2


正確にはこの3条件はGNFAの「特殊形」ということですが、まあすんなり理解できる感じの特徴ではあります。
証明は、一旦任意のDFAをGNFAに変換した上で、このGNFA特殊形の性質を使って正規表現へ変換していくという形をとるようです。
DFA to GNFA in the special form
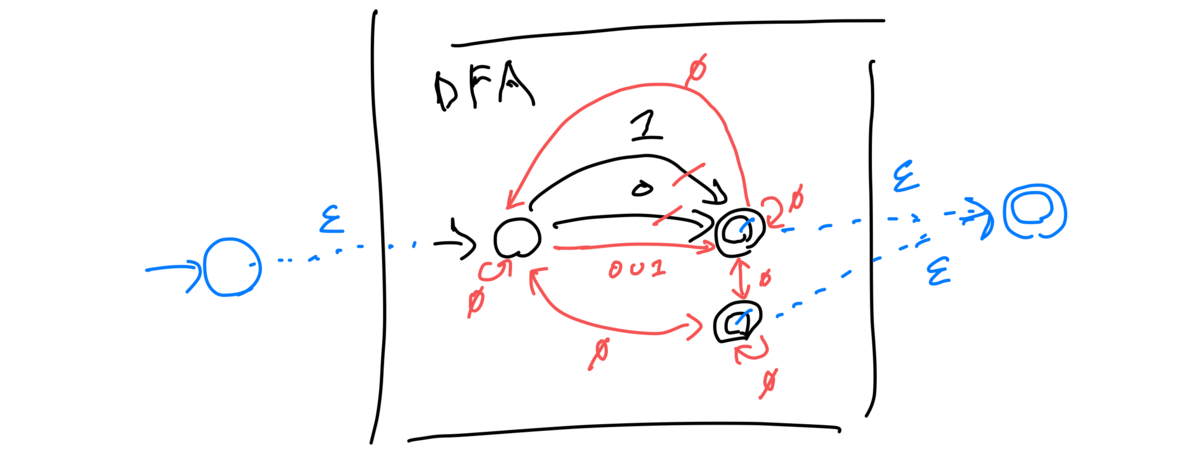
始状態、終状態を新たに作って、矢が複数あったら1本にまとめる、1本もないところはラベルで付け足す。この4操作でGNFAに変換できます。簡単ですね。
CONVERT(G)
続いて、正規表現への変換関数CONVERTを用意します。
CONVERT():
Let
be the number of states of
.
If
, return the expression
with which the single arrow connecting a start and accept state is labeled.
If
, return CONVERT(
) where we construct GNFA
by selecting any state
except for
and letting
3の工程で状態数が1つ減るので、それをk=2になるまで再帰的に呼び出しています。の戻り値が正規表現なので、()で囲んで*で0文字以上とか指定しているところに注意です。
の定義がミソですね(下図参照)

この過程でGNFAの同値性が保たれる(同じ言語を認識する)ことが理解できれば、あとはinductiveにこれがk=2まで降りてくることが証明できます。